
In today's data-driven landscape, a slow database is a critical bottleneck that can cripple application performance, frustrate users, and impact your bottom line. Whether you're running a high-traffic e-commerce site, a complex SaaS application, or a content-heavy platform like those built with Divi, the speed and efficiency of your database are paramount. Many developers and site owners focus on front-end optimizations but overlook the massive performance gains waiting to be unlocked in the data layer.
This article dives deep into the most effective database optimization techniques that seasoned professionals use to ensure their systems are fast, scalable, and resilient. For a comprehensive guide on boosting your database's speed and efficiency, refer to this article on Top Database Optimization Techniques. We'll move beyond generic advice and provide a roundup of 10 essential strategies, complete with practical implementation tips, real-world examples, and actionable steps you can take today.
From foundational concepts like indexing and query tuning to advanced strategies such as sharding and read replicas, you'll gain the knowledge to diagnose performance issues and transform your database into a high-performance engine. Let's explore the techniques that separate sluggish applications from lightning-fast ones.
1. Master the Art of Database Indexing
Indexing is one of the most fundamental and powerful database optimization techniques available. Think of it like the index at the back of a book; instead of reading the entire book to find a topic, you use the index to jump directly to the correct page. Similarly, a database index creates a special data structure that allows the database engine to find records without performing a full-table scan.
This drastically speeds up data retrieval (SELECT queries), especially on large tables with millions of rows. Without an index, a query searching for a specific user in a users table would have to check every single row. With an index on the email column, it can find the user almost instantly.
When and Why to Use Indexing
The primary use case for indexing is to accelerate queries that filter data using WHERE clauses or join tables using ON clauses. It's a foundational step for any read-heavy application, such as e-commerce sites needing to quickly look up products or blogs fetching articles by ID.
Key Insight: A well-placed index can reduce query execution time from several minutes to mere milliseconds. However, indexes are not free. They consume disk space and add overhead to data modification operations (
INSERT,UPDATE,DELETE), as the index must also be updated.
Actionable Implementation Tips
- Analyze Query Patterns: Use your database's query analysis tools (like
EXPLAINin MySQL or PostgreSQL) to identify slow queries and see which ones are performing full-table scans. These are prime candidates for indexing. - Be Selective: Don't index every column. Prioritize columns frequently used in
WHEREclauses,JOINconditions, andORDER BYclauses. Indexing columns with low cardinality (few unique values, like astatuscolumn with only 'active' and 'inactive') is often less effective. - Use Composite Indexes: If your queries frequently filter on multiple columns at once, create a composite (multi-column) index. For a query like
SELECT * FROM orders WHERE customer_id = 123 AND order_date > '2023-01-01', an index on(customer_id, order_date)is far more efficient than two separate indexes.
2. Optimize Your Queries
While indexing sets the stage, the queries themselves are the actors. Query optimization is the process of writing and refining SQL statements so the database engine can execute them as efficiently as possible. A poorly written query can negate the benefits of even the best indexes, leading to slow performance, high CPU usage, and application bottlenecks.
This involves structuring your query to minimize the amount of data read, processed, and returned. Modern databases use sophisticated cost-based optimizers to create an execution plan, but these systems work best when given a well-formed query. Techniques like using specific JOIN types and filtering data early can dramatically influence this plan.
When and Why to Optimize Queries
Query optimization is a continuous process crucial for applications with complex data-retrieval logic or high transaction volumes. It's especially vital when you notice specific application features are slow, or when database server load is consistently high. An optimized query reduces latency, lowers server costs, and enhances user experience.
Key Insight: The database doesn't run the query you write; it runs the execution plan it generates from your query. Small changes in SQL syntax can lead to vastly different, and more efficient, execution plans.
Actionable Implementation Tips
- Analyze the Execution Plan: Use your database’s built-in tools, such as
EXPLAIN(orEXPLAIN ANALYZE) in PostgreSQL and MySQL. This command reveals how the database intends to execute your query, showing which indexes are used and where full-table scans occur. - Avoid
SELECT *: Only request the columns you need. Selecting all columns with*increases data transfer over the network and can prevent the database from using more efficient, index-only scans. - Filter Early and Be Specific: Apply the most restrictive
WHEREclauses as early as possible. This reduces the size of the dataset that needs to be processed in later steps, like joins or aggregations. For further insights, especially when you run into errors, learning more about troubleshooting MySQL query issues can be very beneficial. - Choose the Right
JOIN: Understand the difference betweenINNER JOIN,LEFT JOIN, andRIGHT JOIN. Use the most appropriate type to avoid retrieving unnecessary rows from joined tables, which can be a significant performance drain.
3. Implement Proper Database Normalization
Database normalization is a structural database optimization technique focused on organizing a schema to minimize data redundancy and enhance data integrity. Popularized by Edgar F. Codd, this process involves breaking down large, unwieldy tables into smaller, more manageable, and well-structured ones. By eliminating duplicate data, you prevent update anomalies where changing information in one place fails to update it elsewhere.
This systematic approach ensures that data is stored logically, which simplifies maintenance and reduces the risk of inconsistencies. For example, in an e-commerce system, customer information, orders, and product details are kept in separate, related tables rather than one massive, repetitive table. This clean structure is fundamental to a healthy, scalable database.
When and Why to Use Normalization
Normalization is crucial for applications where data integrity is paramount, especially those with frequent write operations (INSERT, UPDATE, DELETE). It’s a foundational design principle for most online transaction processing (OLTP) systems, such as banking platforms, hospital management systems, and CRMs, where keeping data consistent and accurate is non-negotiable.
Key Insight: Normalization cleans up your data model, making the database more robust and easier to manage. However, achieving higher normal forms can sometimes lead to more complex queries requiring multiple joins, which may impact read performance. It's a trade-off between write efficiency and read speed.
Actionable Implementation Tips
- Target the Third Normal Form (3NF): For most business applications, 3NF provides a good balance between reducing redundancy and maintaining performance. It ensures that all columns in a table are dependent only on the primary key.
- Use Foreign Keys for Integrity: Properly implement foreign key constraints to enforce referential integrity between related tables. This ensures that a record in one table cannot reference a non-existent record in another.
- Consider Strategic Denormalization: For read-heavy applications or specific reporting queries where performance is critical, you might intentionally violate normalization rules (denormalize). This involves adding redundant data to reduce the number of joins needed to fetch information.
- Document Schema Relationships: As you normalize, clearly document the relationships between tables, including primary and foreign keys. This documentation is invaluable for future development and maintenance.
4. Partitioning and Sharding
As a database grows, managing a single, massive table becomes inefficient and slow. Partitioning is a powerful database optimization technique that addresses this by breaking down a large table into smaller, more manageable pieces called partitions. This process can be done vertically (splitting columns into separate tables) or horizontally (splitting rows across different tables or even servers, a practice known as sharding).
This approach drastically improves query performance by allowing the database to scan only relevant partitions instead of the entire table. It also enhances maintainability, as administrative tasks like rebuilding indexes or backing up data can be performed on individual partitions. Tech giants like Instagram and Twitter use partitioning and sharding to manage their enormous datasets of user profiles and tweets.
When and Why to Use Partitioning
Partitioning is ideal for very large tables where queries frequently access only a subset of the data, such as time-series data where queries target a specific date range. It is a critical strategy for applications scaling to handle massive amounts of data and high throughput, as it distributes the load and enables parallel processing, preventing single-server bottlenecks.
Key Insight: Effective partitioning can make a seemingly unmanageable database feel fast and responsive. The key is choosing a partition key that aligns directly with your most common query patterns, ensuring queries can prune (ignore) irrelevant partitions.
The following concept map illustrates the primary types of partitioning and their shared core benefit.
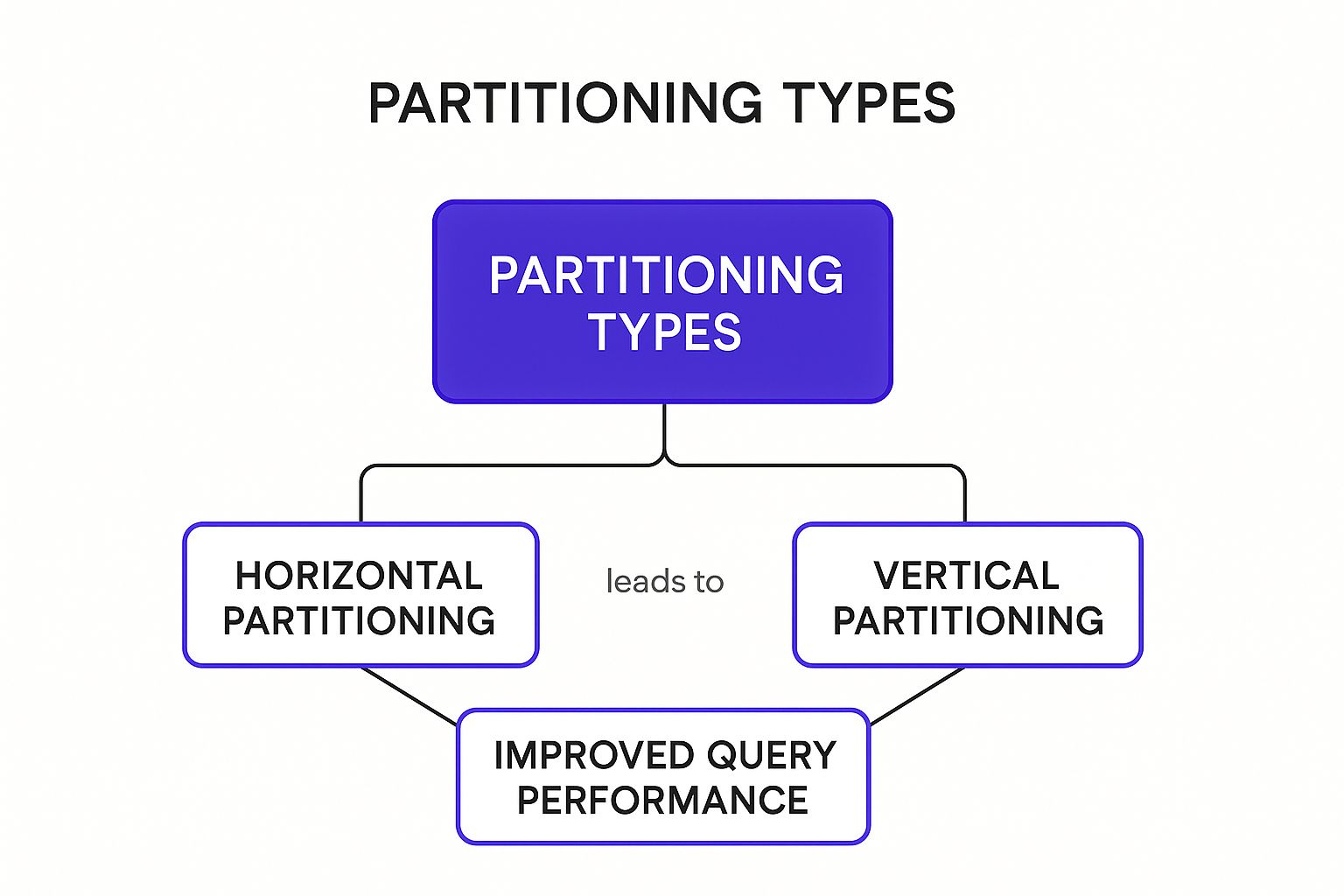
This visualization highlights that whether you split data by rows (horizontal) or by columns (vertical), the fundamental goal is to achieve improved query performance.
Actionable Implementation Tips
- Choose the Right Partition Key: Analyze your
WHEREclauses. For time-series data (e.g., logs, events), use range partitioning on a timestamp column. For distributing load evenly, use hash partitioning on a user ID or a similar high-cardinality column. - Implement Partition Pruning: Ensure your queries are written to take advantage of the partition key. This allows the database engine to automatically exclude partitions that don't contain relevant data, which is where the main performance gain comes from.
- Monitor Partition Balance: If using hash or list partitioning, regularly monitor the size and traffic of each partition to ensure data is distributed evenly. Unbalanced partitions, known as "hot spots," can negate the benefits of this database optimization technique.
5. Implement Smart Connection Pooling
Establishing a database connection is a surprisingly resource-intensive process. It involves network handshakes, authentication, and session setup, all of which introduce latency. Connection pooling is a critical database optimization technique that reuses existing connections rather than creating a new one for every request, dramatically reducing this overhead.
Think of it like a fleet of pre-authorized taxis waiting at an airport. Instead of hailing a new car and verifying the driver each time, passengers grab an available taxi from the queue, making the process much faster. A connection pool works the same way, maintaining a cache of ready-to-use database connections for your application.
When and Why to Use Connection Pooling
This technique is essential for any application that interacts frequently with a database, such as web applications, APIs, and microservices. Without it, high-traffic applications would quickly exhaust server resources by constantly opening and closing connections, leading to poor performance and potential downtime. It's a foundational strategy for building scalable, responsive systems.
Key Insight: Connection pooling moves the cost of connection management from a per-request basis to a one-time setup cost. This not only boosts performance but also prevents resource exhaustion by placing a hard limit on the number of concurrent connections.
Actionable Implementation Tips
- Configure Pool Size Carefully: Set minimum and maximum pool sizes based on your application's expected traffic. A pool that's too small will cause requests to wait for a free connection, while one that's too large wastes memory. Start with a conservative size and monitor performance.
- Set Sensible Timeouts: Configure connection timeout and idle timeout values. A connection timeout prevents an application from hanging indefinitely while waiting for a connection. An idle timeout closes connections that haven't been used for a while, freeing up resources.
- Use Proven Libraries: Instead of building your own, leverage robust, battle-tested libraries. For Java applications, HikariCP is the gold standard for performance. For Node.js with MongoDB, the native driver handles pooling automatically.
6. Implement Smart Caching Strategies
Caching is a powerful database optimization technique that involves storing frequently accessed data in a temporary, high-speed storage layer closer to the application. Instead of repeatedly querying the database for the same information, an application can retrieve it from the cache, which is significantly faster. This reduces the number of round trips to the database, decreases its workload, and dramatically improves application response times.
This approach is highly effective for data that is read often but updated infrequently. For example, tech giants like Facebook and Twitter rely heavily on distributed caching systems like Memcached and Redis to serve social graphs and user timelines almost instantaneously.

When and Why to Use Caching
Caching is ideal for read-heavy applications where performance is critical. Use it to store user session data, application configuration settings, or the results of complex and expensive queries. E-commerce sites, for instance, can cache product details and categories to provide a snappy user experience, even during high-traffic periods.
Key Insight: Effective caching doesn't just speed up your application; it protects your database from being overwhelmed by repetitive read requests. A high cache-hit ratio (the percentage of requests served from the cache) is a strong indicator of a well-implemented caching strategy.
Actionable Implementation Tips
- Identify Cacheable Data: Analyze your application to find data that is accessed frequently but changes rarely. This could be user profiles, product catalogs, or system settings. Avoid caching rapidly changing data, as it can lead to stale information.
- Choose the Right Caching Pattern: Implement a pattern like Cache-Aside, where the application checks the cache first and queries the database only on a cache miss. Alternatively, use a Write-Through cache where data is written to both the cache and the database simultaneously.
- Set Clear Eviction Policies: Your cache has limited size, so you need a strategy to remove old data. Policies like Least Recently Used (LRU) or setting a specific Time-To-Live (TTL) on cached items ensure that your cache remains filled with relevant, fresh data.
- Monitor Your Cache: Regularly track metrics like cache-hit ratio, memory usage, and latency. Monitoring helps you understand if your caching strategy is effective and allows you to fine-tune its performance over time.
7. Embrace Strategic Database Denormalization
While normalization is a core principle of relational database design, denormalization is a powerful, intentional database optimization technique where you introduce redundancy to improve read performance. It involves combining tables or duplicating data to reduce the need for complex and resource-intensive JOIN operations during frequent queries.
This counter-intuitive approach is highly effective in read-heavy environments. For example, a social media feed might denormalize by storing a user's name directly within each post record, avoiding a JOIN to the users table every time the feed is loaded. This trades some storage space and write-time complexity for significantly faster data retrieval.
When and Why to Use Denormalization
Denormalization is a targeted solution for performance bottlenecks, not a general design principle. It is ideal for reporting dashboards, analytics platforms, and applications where read speed is a critical business requirement. By pre-computing and storing data in a query-friendly format, you drastically reduce the workload on the database for common read requests.
Key Insight: Denormalization is a strategic trade-off. You accept increased storage costs and the complexity of keeping redundant data consistent in exchange for massive gains in read query performance. It's about optimizing for how your data is consumed.
Actionable Implementation Tips
- Target Read-Heavy Scenarios: Identify the slowest, most frequent read queries that involve multiple
JOINs. These are your primary candidates for denormalization. - Maintain Data Consistency: Since you are duplicating data, you must have a strategy to keep it synchronized. This can be handled through application-level logic, database triggers, or scheduled jobs that update the redundant data.
- Use Materialized Views: If your database supports them (like PostgreSQL or Oracle), materialized views are an excellent way to implement denormalization. They store the result of a query in a physical table that can be indexed and refreshed periodically.
- Document Everything: Clearly document which parts of your schema are denormalized and why. Explain the mechanisms you've put in place to maintain data consistency so future developers understand the design choices.
8. Stored Procedures and Functions
Leveraging stored procedures and functions is a classic yet powerful database optimization technique that shifts application logic directly onto the database server. These are pre-compiled SQL code blocks that can execute complex operations, from data validation to intricate transaction processing. By running on the server, they minimize the back-and-forth data transfer between the application and the database.
Instead of an application sending multiple SQL statements to process an order, it can make a single call to a stored procedure like EXECUTE process_new_order. The server handles all the internal logic, drastically reducing network latency and improving overall performance. This centralization also ensures that business rules are applied consistently across all applications accessing the database.
When and Why to Use Stored Procedures and Functions
Stored procedures are ideal for encapsulating multi-step business logic that is executed frequently. Common use cases include complex transaction processing in banking systems, order fulfillment workflows in e-commerce platforms, or enforcing sophisticated business rules in an ERP system. They enhance security by abstracting direct table access and preventing SQL injection through parameterization.
Key Insight: Stored procedures reduce network traffic and compile execution plans once, reusing them for subsequent calls. This combination offers a significant performance boost for repetitive, complex database tasks compared to sending ad-hoc SQL from an application.
Actionable Implementation Tips
- Target Repetitive, Complex Logic: Identify business operations that require multiple queries and are called frequently. These are prime candidates for conversion into a stored procedure to maximize performance gains.
- Keep Procedures Focused: Design procedures to perform a single, logical unit of work. Avoid creating monolithic procedures that do everything; modular, smaller procedures are easier to debug, maintain, and reuse.
- Implement Robust Error Handling: Use
TRY...CATCHblocks (in SQL Server) or equivalent exception handling mechanisms in your database system to manage errors gracefully within the procedure itself. - Use Version Control: Treat your stored procedure code like any other application code. Store it in a version control system like Git to track changes, collaborate with your team, and manage deployments effectively.
9. Read Replicas and Load Balancing
As your application scales, a single database can become a bottleneck, especially when it has to handle a high volume of both read and write operations. Read replicas are one of the most effective database optimization techniques for this scenario. This strategy involves creating one or more read-only copies of your primary (master) database. A load balancer then directs all incoming read queries to these replicas, while write operations (INSERT, UPDATE, DELETE) are sent exclusively to the primary database.
This separation of concerns is a game-changer for read-heavy applications. The primary database can dedicate its resources to efficiently processing writes, ensuring data integrity and speed. Meanwhile, the replicas handle the demanding task of serving data, which often constitutes the bulk of an application's workload, such as fetching user profiles or product listings. This architecture dramatically improves scalability and responsiveness.
When and Why to Use Read Replicas
This technique is essential for applications with a high read-to-write ratio, where the number of SELECT queries vastly outnumbers data modifications. E-commerce platforms, content management systems, and social media feeds are classic examples. By distributing the read load, you prevent the primary database from getting overwhelmed, which improves performance for all users and increases the system's overall availability.
Key Insight: Implementing read replicas effectively decouples read and write workloads, allowing your database infrastructure to scale horizontally. This not only boosts performance but also enhances fault tolerance; if a replica fails, traffic can be redirected to others without impacting write operations.
Actionable Implementation Tips
- Monitor Replication Lag: Keep a close watch on the delay between a write occurring on the primary and it being reflected on the replicas (replication lag). Significant lag can lead to serving stale data, so set up alerts to monitor this metric.
- Implement Read/Write Splitting: Your application's data access layer must be smart enough to route queries correctly. Write queries go to the primary, and read queries go to the replicas. Many frameworks and connection pools offer this functionality out of the box.
- Plan for Replica Promotion: Have a clear, automated plan for promoting a read replica to a new primary database if the original primary fails. Services like Amazon RDS handle this seamlessly, but it's a critical consideration for self-managed setups.
- Use a Load Balancer: Place a load balancer in front of your read replicas to distribute traffic evenly. This prevents any single replica from becoming a bottleneck and simplifies adding or removing replicas from the pool.
10. Embrace Proactive Database Maintenance
Regular maintenance is a crucial database optimization technique that prevents performance degradation before it starts. Think of it like servicing a car; routine checks and tune-ups ensure it runs smoothly and efficiently. In a database context, this involves tasks like updating statistics, rebuilding indexes, and managing data file growth to keep the system in peak condition.
A database's query optimizer relies on statistics, which are metadata about data distribution in tables and indexes, to choose the most efficient execution plan. Outdated statistics can lead the optimizer to make poor choices, resulting in slow queries. Regular maintenance ensures these statistics are fresh and accurate.
When and Why to Use Maintenance
Proactive maintenance is non-negotiable for any database that experiences regular data changes (INSERT, UPDATE, DELETE). It's especially critical for systems with high transaction volumes, like e-commerce platforms updating product catalogs or banking systems processing daily transactions. Without it, index fragmentation and stale statistics will inevitably slow performance over time.
Key Insight: Database performance doesn't just degrade; it erodes silently. Proactive maintenance is the practice of fighting this erosion, ensuring that query plans remain optimal and data access stays fast as the database evolves.
Actionable Implementation Tips
- Automate Routine Tasks: Use built-in tools or scripts (like PostgreSQL's autovacuum or SQL Server Maintenance Plans) to automate tasks like updating statistics and rebuilding indexes. Schedule these jobs to run during off-peak hours to minimize impact.
- Monitor Database Growth: Keep an eye on table and index sizes. Unchecked growth can lead to storage issues and slower backup and restore times. Plan for capacity and implement archiving strategies for historical data.
- Rebuild or Reorganize Indexes: Over time, indexes can become fragmented, which makes them less efficient. Periodically rebuild or reorganize frequently modified indexes to compact them and improve read performance.
- Set Up Health Check Alerts: Configure monitoring to alert you to critical issues like low disk space, long-running queries, or failed maintenance jobs. Early detection is key to preventing major problems.
Top 10 Database Optimization Techniques Comparison
| Technique | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Database Indexing | Medium – requires schema design and ongoing maintenance | Extra storage and CPU for index updates | Faster SELECT queries, improved JOIN speed | Query-intensive databases, OLTP systems | Dramatic query speedup, supports unique constraints |
| Query Optimization | High – needs SQL expertise and detailed analysis | Modest – mainly CPU and developer time | Significant performance gains, reduced resource use | Existing deployments needing query tuning | Performance improvements without hardware changes |
| Database Normalization | Medium to High – schema redesign with multiple tables | Moderate – complexity in relations and JOINs | Reduced data redundancy, improved integrity | Systems requiring data consistency and maintainability | Eliminates redundancy, prevents anomalies |
| Partitioning and Sharding | High – complex setup and management | High – multiple servers/databases and coordination | Scalable performance, parallel processing | Large-scale, high-volume datasets | Improved scalability and manageability |
| Connection Pooling | Low to Medium – configuration and monitoring | Modest – memory for pooled connections | Reduced connection overhead, faster response times | Web applications with high DB connection demand | Efficient resource utilization, lowers latency |
| Caching Strategies | Medium – involves additional layers and consistency handling | Moderate to High – memory and cache infrastructure | Reduced DB load, faster query responses | Read-heavy applications, high traffic systems | Dramatic load reduction, improved scalability |
| Database Denormalization | Medium – intentional schema redundancy | Higher storage due to duplication | Faster read performance, simpler queries | Read-heavy, reporting, data warehousing | Improves read speed, reduces JOIN complexity |
| Stored Procedures & Functions | Medium – requires procedural coding and version management | Modest – runs within DB engine | Reduced network traffic, consistent business logic | Complex transactional workflows | Pre-compiled, secure, reusable logic |
| Read Replicas & Load Balancing | High – infrastructure complexity and sync management | High – extra DB instances and network resources | Improved read throughput, higher availability | Systems with high read/write separation needs | Scales reads, improves fault tolerance |
| Database Statistics & Maintenance | Medium – scheduled tasks and monitoring setup | Moderate – CPU and I/O during maintenance windows | Maintains performance, prevents degradation | All production DBs requiring long-term health | Optimizes performance, ensures integrity |
Building a Faster Future for Your Application
The journey through the world of database optimization techniques reveals a core truth: a high-performance database is not a happy accident, but the result of intentional, continuous effort. The ten strategies we've explored, from foundational indexing and precise query optimization to advanced scaling with read replicas and sharding, are not just isolated fixes. They are interconnected components in a holistic system designed for speed, reliability, and growth.
Mastering these concepts transforms your role from a reactive troubleshooter into a proactive architect. You move beyond simply fixing slow queries to building systems that are inherently resilient to performance degradation. This is where the real value lies, especially for developers and agencies working within the WordPress and Divi ecosystem, where plugin conflicts and complex queries can easily bog down a site.
From Theory to Actionable Strategy
The path forward is clear. The first step is not to blindly implement every technique, but to diagnose before you prescribe. Use database profiling tools, EXPLAIN plans, and application performance monitoring (APM) to pinpoint your specific bottlenecks. Is latency high due to a few complex queries? Query optimization and indexing are your starting points. Is your server overwhelmed by a sheer volume of connections? Connection pooling and caching are your immediate priorities.
Here are your actionable next steps:
- Audit Your Indexes: Review your most frequently run queries. Ensure that columns used in
WHERE,JOIN, andORDER BYclauses are properly indexed. Look for and remove any redundant or unused indexes that add overhead. - Analyze Your Slow Query Log: Activate and regularly check your database's slow query log. This is the most direct way to identify the queries that are causing the most significant impact on your application's performance.
- Evaluate Your Caching Layer: Determine if you are leveraging caching effectively. For a Divi or WooCommerce site, this means implementing a robust object cache (like Redis or Memcached) to reduce repetitive database calls generated by themes and plugins.
- Plan for Scale: Even if your traffic is moderate today, think about tomorrow. Consider if your data model would benefit from partitioning or if your infrastructure is ready for read replicas. Making these architectural decisions early can save immense effort later.
Ultimately, a deep understanding of these database optimization techniques is a powerful competitive advantage. It empowers you to build faster websites, more scalable applications, and deliver a superior user experience. By investing in the health and efficiency of your data layer, you are investing directly in user satisfaction, conversion rates, and the long-term, sustainable success of your digital projects.
Ready to apply these optimization principles to your Divi websites without wrestling with complex server configurations? The plugins and tutorials from Divimode are engineered for peak performance, helping you build faster, more efficient sites from the ground up. Explore our solutions at Divimode to see how we can help you build better and faster.
More Articles You Will Like





